Week 11: Success!
Johnny Y -
This week, after speaking with my advisor, I implemented several changes to the logistic regression classifier, specifically to the input feature data. Recall that the original feature data was a numeric version of each day’s posts along with the predicted ARIMA price change. I replaced the numeric post data with the proportion of the words in the posts that were positive and negative, respectively. To determine whether a word was positive or negative, I used Bing Liu’s lexicon (which is based on consumer reviews). Then, instead of the raw predicted ARIMA price change, I used the percentage change, and I also added the ARIMA up/down/no-change prediction as a feature. To implement these changes, I had to create new training and test datasets. I then integrated the new datasets with the LR model, but the results were still not great. I then increased the # of iterations to 50, decreased the learning rate (which affects the magnitude of the changes that the model makes to its assumptions – too big can lead to the model not retaining enough information), and tried several tests to ensure that the model was learning properly. However, these changes did not have the desired effect.
I then tried a different set of features, based on a paper I read which analyzed Twitter posts to predict stock movements. This paper had the most success using tweet volume, so my new set of features had 3 features: total number of words with sentiment, the ratio of positive words to negative words, and ARIMA’s predicted percentage change. Again, I had to create a new data set for these features. Unfortunately, this still didn’t work. At my advisor’s suggestion, I created a cryptocurrency/trading-specific lexicon of positive and negative words. While this improved performance, it still only could predict 2 of the 3 classes.
I then realized that there was still data I hadn’t used – the comments on the Reddit posts I was analyzing. Thus, I added features from the comments data: total number of words with sentiment and the ratio of positive to negative words in the comments. With the comments data, the model finally worked!
Results:
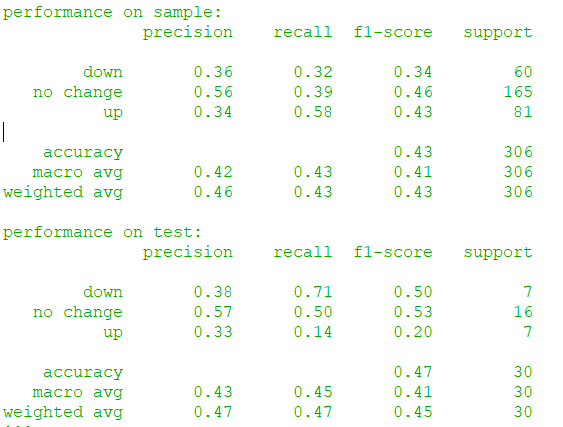
Of course, there’s still much room for improvement. I plan to add negated concepts to the lexicon (ex: if green is positive, then “not green” should be negative). I’ll also continue expanding the lexicon to make it more comprehensive.
Comments:
All viewpoints are welcome but profane, threatening, disrespectful, or harassing comments will not be tolerated and are subject to moderation up to, and including, full deletion.