It’s Storming Outside and Inside: Organizing the Chaos of Speech Processing

8:57 am. High winds. Current temp: 26º. Feels like: 19º. Looks like: 72º
The wind almost knocked me down as I was walking across Charles River from CrossFit to the lab this morning. The day after a snowstorm is apparently worse than the actual snowstorm because it looks nice but the temperature drops 20 degrees, and the wind gusts rise to 36 mph. I did not know this.
The revolving doors at the entrance of Mass Eye and Ear were very welcoming. Today, I met the director of the lab and my advisor, Dr. Kristina Simonyan. I completed all of the health and safety training, so now I can be added to the IRB protocol. By the end of the week, I should be added to the lab server and database, to give me access to speech samples and existing programs. Until then, I have been reading Intro to Speech Processing which breaks down the phonetics of speech and how to analyze samples computationally. Because I’m not sure yet what current research I can share publicly, for now, I can show you what I have been exploring on my own:
I set myself a small task: converting my voice into an image in Python. I opened Audacity, a sound recording software, and recorded a two-second sample of my voice: “this is a test.”
A spectrogram is an image showing amplitude (color) and frequency (y-axis in Hz) across a period of time (x-axis in seconds). Here is what my spectrogram looked like:
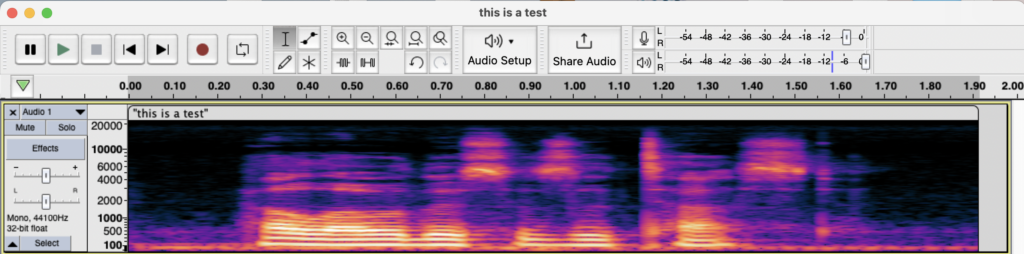
Next, I labeled parts of the sentence I recognized in the spectrogram:
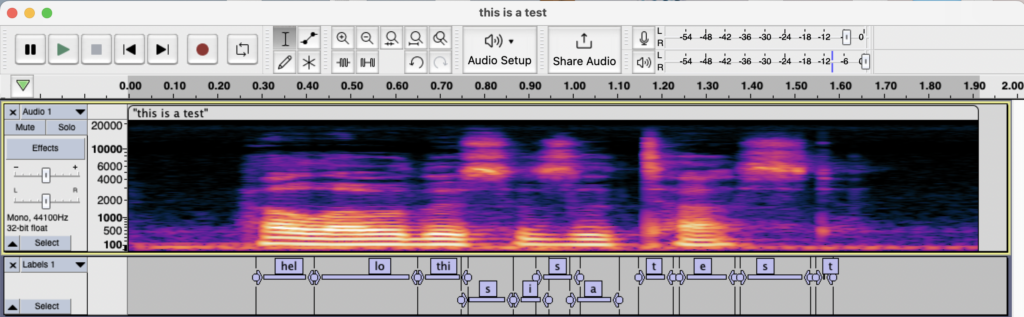
Now the challenge was transporting this data into Python. When you export the labels into a text file, Audacity saves the time bounds along with the min/max frequency for each label:

After importing the audio file, text file, and additional code into the Python audio library ‘librosa’, the following image returned:

Success! (After a lot of troubleshooting). The image above now contains statistical data that a computer can read. Each pixel contains three numbers for red, green, and blue (RGB). Example: pixel_x = [22 98 14]. For a computer, these three numbers hold computational value.
This small project was very simplified, but it helped me learn how to use Audacity and Python together. I am also learning how to code a model that determines whether an image is a dog or a road, but I will save that for the next post. Again, I am not sure how much of the laryngeal dystonia project I can share with you, but I will try my best.