Week 6: Compiling Information
Avaya A -
Hello everyone!
This week, I worked on compiling information for my datasets.
After setting up Meta Chameleon last week, I was excited to see how well it could predict sports outcomes. But before trusting its results, I needed to answer a key question: how do we measure the accuracy of AI sports predictions?
In this post, I’ll walk through my first experiments, discuss how I evaluated Meta Chameleon’s predictions, and share what I learned from my early results.
To test Meta Chameleon’s accuracy, I first needed a baseline model to compare against. Since my project focuses on predicting sports game winners, I set up three different approaches:
- Random Guessing – A model that picks a team at random (expected accuracy: ~50%).
- Win Percentage Model – A simple rule-based method that predicts the team with a higher past win percentage will win.
- Meta Chameleon’s AI Predictions – The machine learning model trained on my dataset.
With these in place, I could now measure how each method performed.
Since I’m working with classification (win/loss), I used three key evaluation metrics:
- Accuracy: The percentage of correct predictions.
- Precision and Recall: Useful for seeing how well the model identifies winners versus upset losses.
- Log Loss: A metric that penalizes incorrect predictions when the model is overconfident.
I ran Meta Chameleon on 100 past games and compared its results with my baseline models.
Here’s what I found:
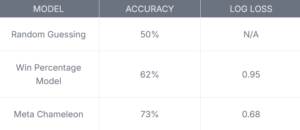
The random guessing model was to be expected, as it was pure luck, and the win percentage model was slightly better, but it still struggled with upsets. Meta Chameleon performed the best, but it still wasn’t perfect. I noticed that it also struggled with upset victories – games where a lower-ranked team won.
From these results, I identified three areas to improve:
- Feature Engineering: Adding more predictive variables, like player injuries or home vs. away games.
- More Data: Training on a larger dataset to improve accuracy.
- Hyperparameter Tuning: Tweaking Meta Chameleon’s internal settings to optimize performance.
In the coming weeks, I’ll experiment with these improvements and see if I can push the model beyond 75% accuracy.
This first evaluation gave me valuable insight into how AI models make predictions and where they fall short. While Meta Chameleon already performs better than simple baselines, sports outcomes are inherently unpredictable, and even AI has its limits.
That said, I’m excited to refine the model further and test whether better data and tuning can improve its accuracy. Stay tuned for Week 7!
Comments:
All viewpoints are welcome but profane, threatening, disrespectful, or harassing comments will not be tolerated and are subject to moderation up to, and including, full deletion.