Week 4 (3/27) – Converting All The Music
Edward W -
This week’s goal: Convert all of the music I plan to use for my survey into the same sound font.
Apologies for how late my blog post was this week! I greatly underestimated the amount of time I’d need to transcribe all my pieces, so this blog post is much later than I would have hoped. Nevertheless, I hope you enjoy what this week has in store, especially as the first half of the project slowly draws to a close.
So, what is a sound font?
I’ve touched a lot on sound fonts throughout my project, so I think it’s very important that I elaborate on what they are and how I am planning on using them in my project.
Just like how a font is used for text that you see, a sound font is used for sound that you hear, more specifically music. It is a collection of samplings from multiple different instruments that are used for playing back MIDI files. Just like how two of the same instrument won’t sound the same because there are differences in the quality, construction, and player between two instruments, sound fonts sound different from other sound fonts because of the differences in the quality of the equipment used to record samples of the instruments, the specific sound of the instruments used for the sampling, and even what settings a sound font is created for (more of a solo instrumental setting? or an ensemble?).
It is very important that for the survey, I use the same sound font between different samples, not because it necessarily “gives away” the AI generated music, but because having different sound fonts in the survey adds unnecessary noise to the final results I get from my survey, and it’s harder to draw a good conclusion from the data I collect.
Allegro Music Transformer, the neural network I used for my song generation, uses the FluidSynth sound font, whereas the sound font I’m using for my seeds and original compositions are all in MuseScore’s MS Basic sound font, so it can end up being easier to tell the two apart through their sound fonts. In the end, I settled on converting everything to MuseScore’s Muse Sounds sound font, just because I think it sounds better and will be more consistent for the survey.
Below, I wanted to add some audio samples, because hearing the difference between the sound fonts is always better than reading my descriptions of them.
Sound Font |
|||
FluidSynth |
MS Basic |
Muse Sounds |
|
Bach |
|||
Mozart |
|||
Chopin |
|||
Prokofiev |
|||
Me |
In grey, I’ve highlighted the sound fonts I used for each audio clip. You can see that Muse Sounds performs much better for solo compositions; the piano sound that it creates feels much richer and less robotic compared to the MS Basic music. But for ensembles, MS Basic creates a better balance between all the instruments compared to Muse Sounds, even if it sounds a bit robotic. Either way, I am using a mix of the two in the final survey, with Muse Sounds for solo pieces and MS Basic for ensemble pieces.
More about what I did this week…
I spent most of this week taking the resulting WAV files that Allegro Music Transformer generated and feeding them through MuseScore 4’s sound fonts. My only issue with Allegro Music Transformer is that there is no option for the neural network to output MIDI files (which MuseScore accepts in its UI), so I have to painstakingly take a WAV file and a corresponding PNG of the music and parse together the final piece into a MIDI file that MuseScore can use. I’ve already attached the WAV files that Allegro Music Transformer generates (they’re in the FluidSynth column of the audio file grid up above), so here are examples of the PNGs that I have to use to transcribe the final pieces:
Bach |
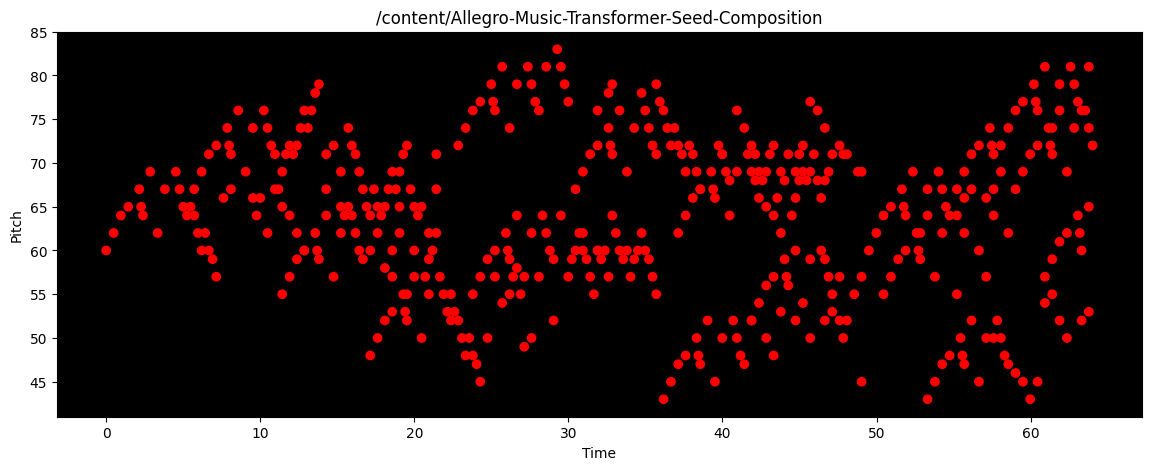 |
Mozart |
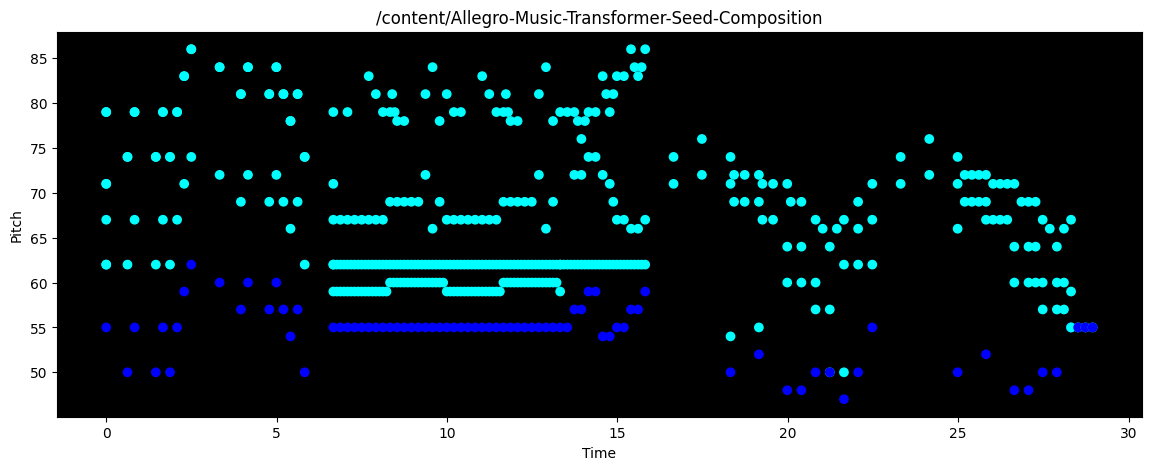 |
Chopin |
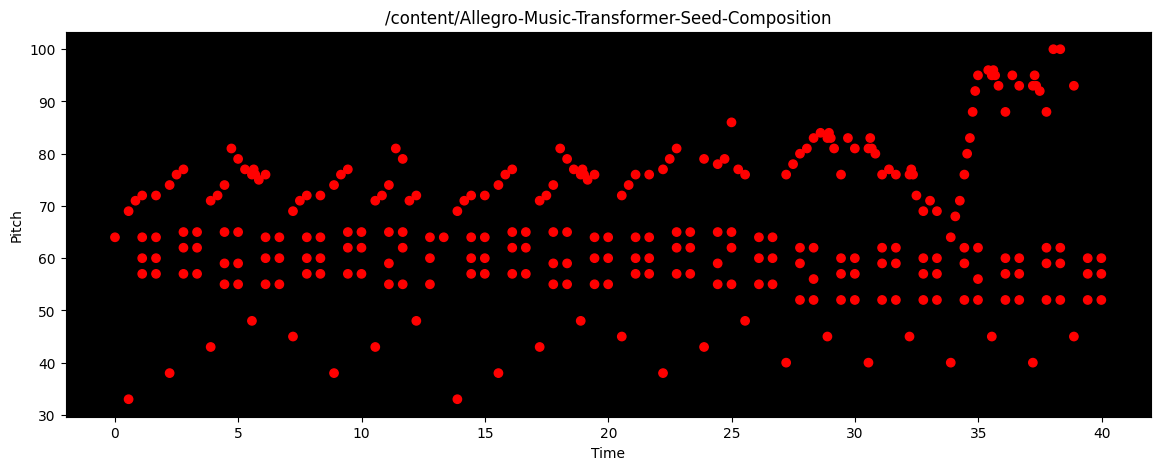 |
Prokofiev |
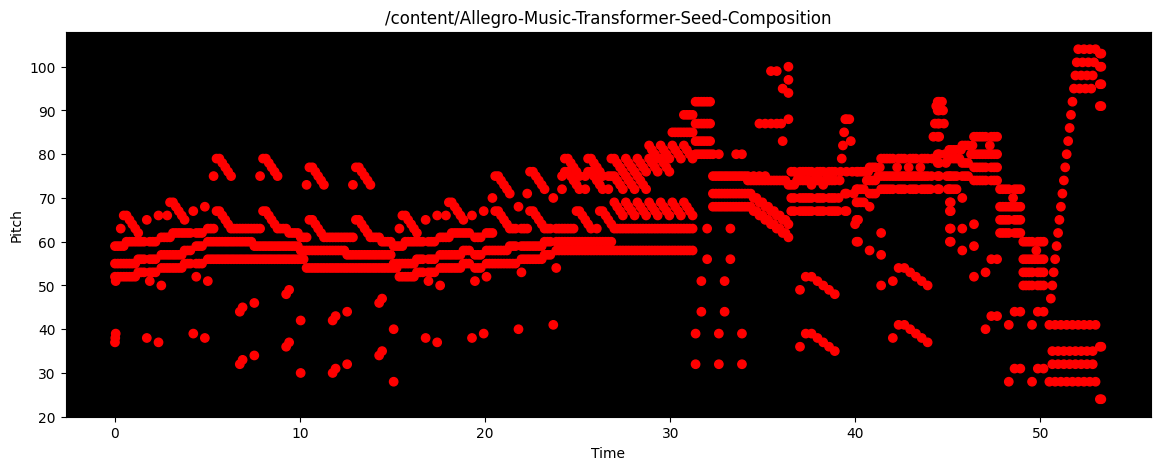 |
Me |
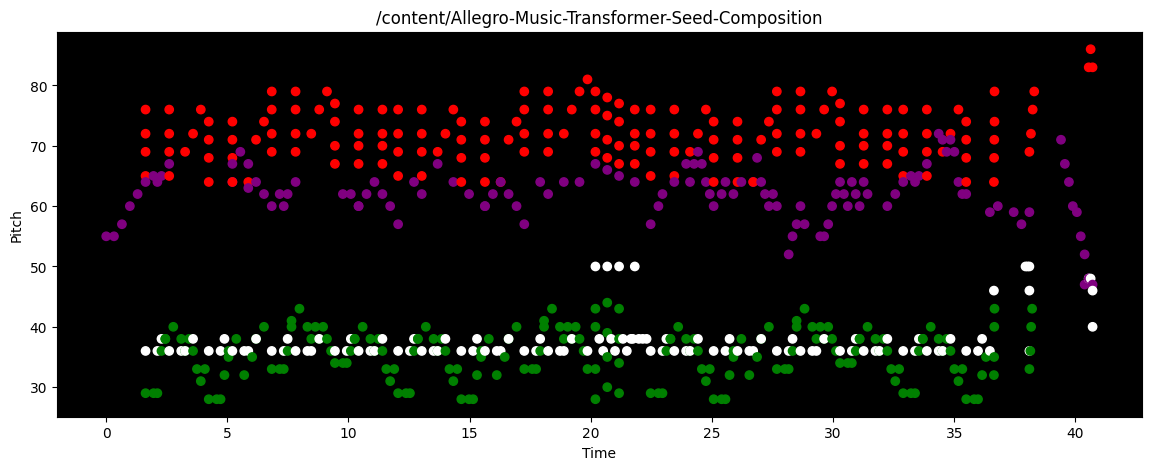 |
The transcription process is painstakingly slow, especially because I have to write down the music the AI generates based on what I hear and see, which ends up being a bunch of guesswork with all the dots in the PNGs. In the end, I was very happy with the results, but it ended up being a lot more work than I anticipated for this week.
Next week’s objective
Next week, I’ll be working on the survey in Google Forms. I am so excited to be able to finally get the survey out, but there will definitely be some hurdles, especially since it’s difficult for me to import audio files into Google Forms and use them as answers. I’m considering making the actual survey in Google Forms so that it has no audio files, but it links to a website on GitHub that contains all the audio files. It’s still in the works, so you’ll get to see the updates next week!
As always, thank you for your supports, and I’ll see you in the next one!
– Eddie 😛
Comments:
All viewpoints are welcome but profane, threatening, disrespectful, or harassing comments will not be tolerated and are subject to moderation up to, and including, full deletion.